
Mysql
mysql
Mysql介绍
- java企业级开发离不开数据库
- 数据是所有软件体系中核心存在 (DBA职位)
只会写代码,学好数据库,混饭吃
操作系统,数据结构 ! 不错的程序猿
离散数学,数字电路, 体系结构, 编译原理 + 经验 大佬
1. 数据库(DB, DataBase)
数据的仓库
SQL: 可以存储大量数据 500万以下都没问题
数据库分类(SQL/NOSQL)
- 关系型数据库(SQL)
- Mysql, Oracle, Sql Server, DB2, SQLlite
- 通过表和表之间, 行和列之间的关系进行数据存储.
- 菲关系型数据库(NOSQL)
- Redis, MongDB
- 存储对象,通过对象的自身属性. 而且使用key-value的关系存储的
==DBSM(数据库管理系统)==
- 数据库的管理软件, 管理和维护我们的数据
- MySql 就是DBMS
Mysql操作语句
| 操作语句 | 作用 |
|---|---|
| mysqld - install | 安装数据库(在bin目录下) |
| mysqld –initialize-insecure –user=mysql | 初始化数据文件 |
| flush privileges; | 刷新权限 |
| net start mysql | 启动Mysql服务 |
| net stop mysql | 结束Mysql服务 |
| exit | 退出Mysql |
InnoDB和MyISAM
- 现在都是默认使用InnoDB
- MySAM 比较老,以前用
区别:
| MySAM | INNODB | |
|---|---|---|
| 1. 事务 | 不支持 | 支持(ACID) |
| 2. 数据锁定方式 | 表锁定 | 行锁定,表锁定 |
| 3. 外键约束 | 不支持 | 支持 |
| 4. 全文索引 | 支持 | 不支持 |
| 5, 表空间大小 | 小 | 大,约为MySAM的两倍 |
| 6. 索引 | b+树 | b+树 |
在物理空间:
所有数据库都是以文件形式存储在data目录下,一组文件对应一个数据库,本质还是文件存储
Mysql引擎
- INNODB在数据库上只有一个*.frm, 以及上级目录的ibdata1文件
- MySAM
- *.frm 表结构
- *.myd 数据文件(data)
- *.MYI 索引文件(index)
数据库操作语句
书写顺序
select – from – where – group by – order by
sql
1 | -- 查看有什么数据库 |
数据库聚合函数
聚合函数: 他们只运行非空值,如果有空值将不会计算在内
而且默认重复值会被取到
sql
1 | -- 基本计算 |
| having | where |
|---|---|
| 只能判断select过的列名 | 能判断所有列名 |
| 其他差不多 |
sql
1 | -- 家早va的并且 订单总额大于100 |
CURD
增删改查
查询
查询/排序
sql
1 | -- 自动那个提交状态 |
内连接查询:
复合主键: 表中主键数量超过一列
sql
1 | -- inner可以省略 |
外连接查询:
内连接如果不满足 on 的条件不会返回
外连接会以 left/right 为主表 不满足也会返回
outer join (outer可以省略)
- 两种:
- 左连接: left join (一般情况使用左连接)
- 右链接: right join
sql
1 | -- 多表连接 |
其他链接查询
- 自然连接 natural join:
数据库引擎自动匹配 不建议使用 - 交叉连接:
将两个表的数据交叉组合(三种饮料和三种杯子尺寸 交叉连接出所有状态)
sql
1 | 表1 CROSS JOIN 表2 (建议使用) |
- 联合查询(UNION)
将多个查询结构集,合成一个 列数要相同, 列明取第一个查询语句
sql
1 | select 1... union select 1... union select 1... ... |
复杂查询
sql
1 | -- 子查询(嵌套查询) |
相关子查询
sql
1 | -- 在嵌套查询中有用到嵌套外的数据 (缺点: 慢,内存消耗高) |
子查询在 select 和 from中使用
sql
1 | -- 计算和和平均值做差 在select中 |
插入/复制
sql
1 | -- 增加数据 |
更新/删除
sql
1 | -- 更新 |
一些函数、关键字
sql
1 | -- 判断空 |
关键字
sql
1 | -- in/not in |
视图
视图数据是同步的(数据同步的)
创建视图时 不使用 Distinct / union 以及 sum / group by … 聚合函数 的view 就是可更新表
视图可以减小数据库设计改动的影响 简化查询操作
sql
1 | -- 创建视图 |
存储过程
sql
1 | -- 创建函数(存储过程) |
sql
1 | -- 执行过程 |
数据结构
sql 可以存的格式
- String
- Number
- Data and Time
- Blob
- Spatial
1. 常见的String
| Name | MAX | |
|---|---|---|
| 1 | char() | 固定长度 |
| 2 | varChar() | 65000 Characters(~64kb) |
| 3 | mediumText | 16MB |
| 4 | longT`ext | 4GB |
| 5 | TinyText | 255 bytes |
| 6 | Text | 64kb |
2. 整数类型
| Data type | Bytes | |
|---|---|---|
| 1 | TINYINT | 1 |
| 2 | SMALLINT | 2 |
| 3 | MEDIUMINT | 3 |
| 4 | INTEGER | 4 |
| 5 | BIGINT | 8 |
3. 浮点数
| Data type | explain | |
|---|---|---|
| 1 | Decimal(P, S) | p: 位数 s: 小数 位 (比较精准) |
| 2 | Dec/Numeric/Fixed | 和上面名字不同 |
| 3 | Float / Double | 科学计数 不是特别精准 |
4. 时间
存储时间
- Data:
- Time:
- Datetime: 8b
- Timestamp: 4b (因为4b所以会有2038问题(时间存储会出问题) 好奇可以搜索一下)
- Year
5. blob类型
存储所有的二进制结构的文件: 图片 pdf word 等等
| Data type | size | |
|---|---|---|
| 1 | TinyBlob | 225b |
| 2 | Blob | 65kb |
| 3 | mediumBlob | 16mb |
| 4 | LongBlob | 4gb |
因为将数据库中存入文件会将数据库变得很大. 而且读取效率 备份时间 以及开发代码 都会变得多 所以考虑存储文件前 线考虑这些问题
6 Json
mysql 8 以后开始支持
Json
写: Json_Object(json对象)
查询
sql
1
2select id, properties -> '$. name.childName' from *** where ***
properties ->> '$. name.childName' : 值读取值- json函数 很多都比较方便 可以试试
. 布尔, 集合和枚举
这一部分只是大概介绍一下: 因为需要很多实践就不放在这里了
如果需要设计一个数据库:
- Understand the requirements(了解需求是很重要的)
- 建立 概念,逻辑,实体 模型
模型建立
数据库概念模型实际上是现实世界到机器世界的一个中间层次。侧重于具体的功能在实际世界的实现,
逻辑模型在概念模型的基础上更细化。 更侧重于数据库的实现

概念模型和概念模型
实体模型:具体的数据库模型
主键:数据库标识(唯一的) 还可以复合主键
外键: 如果一个字段X在A表中是主关键字,而在另外一张表B表中不是主关键字,则字段X称为表二的外键;
外键约束: 虽说主键尽量不可修改 但是外键有 对应修改和删除的操作:
==on delete/update 规则:==
CASCADE:级联
(1)所谓的级联删除,就是删除主键表的同时,外键表同时删除。
NO ACTION(非活动,默认)、RESTRICT:约束/限制
当取值为No Action或者Restrict时,则当在主键表中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。(即外键表约束主键表)
NO ACTION和RESTRICT的区别:只有在及个别的情况下会导致区别,前者是在其他约束的动作之后执行,后者具有最高的优先权执行。
SET NULL
当取值为Set Null时,则当在主键表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(一样是外键表约束主键表,不过这就要求该外键允许取null)。
标准化
数据库七大约束中三范式最为重要 : 保证了数据库的不冗余, 便捷等
数据库三范式
- 表的每一列都是不可分割的原子数据
- 非主键必须完全依赖于主键
- 非主键必须直接依赖主键(不能有传递和间接关系)
实际应用
其实这些范式我记的并不全面,而且实际应用当中 并不一定严格准守这些约束 尽可能的消除冗余就好了。
- 但是 尽量先建立模型 , 在建立数据库, 否则会很糟糕。
- 但是 并不一定都需要建模, 因为建模可能和实际不符合,并且过于复杂且无用,值需要为当下确定一个可行方案, 而不是想要设计一个永远不出问题的模型
- 模型正向工程: 我们创建了模型 – 将模型转换为脚本 – 执行 (可以同步修改表和模型)
- 模型逆向工程: 将数据库转换为 模型
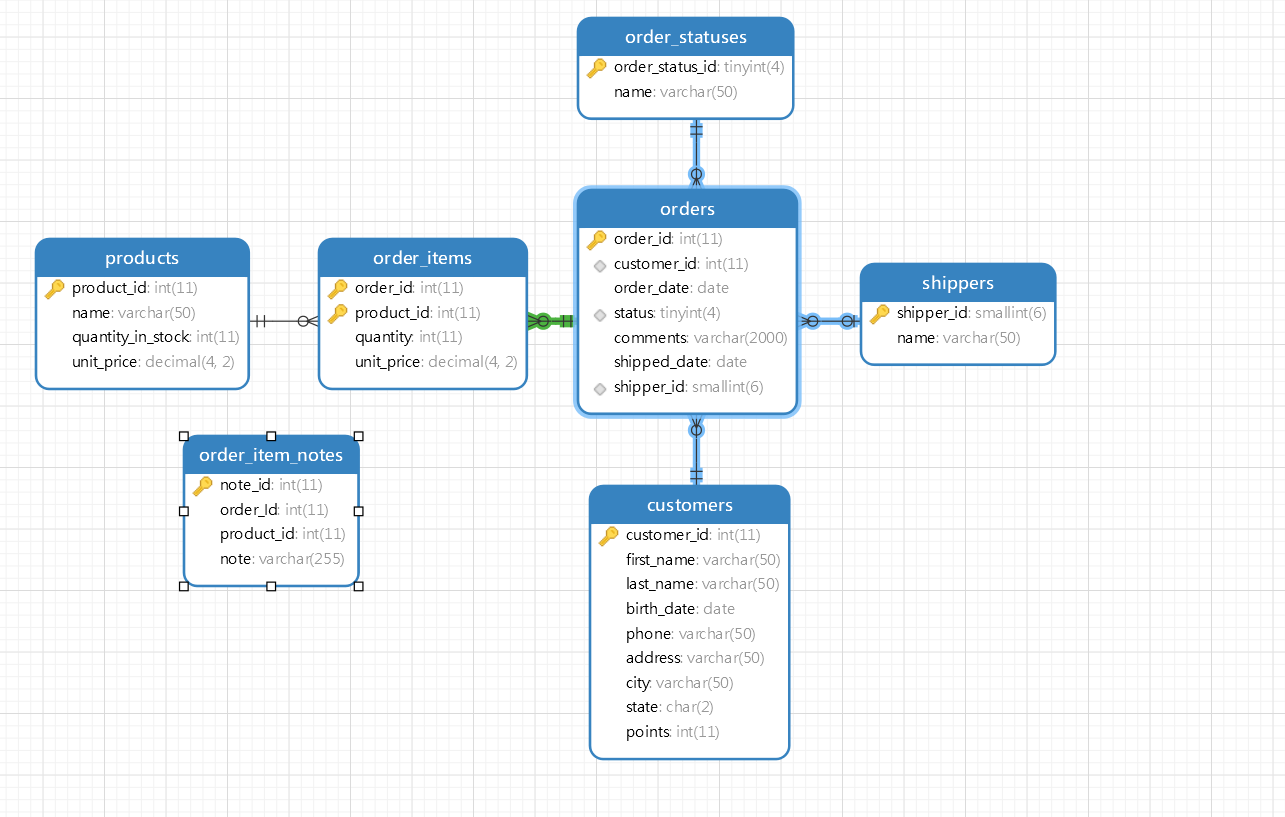
image.png
- 练习 航空系统 链接
数据库保护
因为一直在本地运行,如果在真实项目要考虑安全问题
用户和权限
CURD 管理可访问到数据库的用户
sql
1 | CREATE USER join11 @172.0.0.1 IDENTIFIED BY '123123'; |
| Privilege | Column | Context |
|---|---|---|
CREATE |
Create_priv |
databases, tables, or indexes |
DROP |
Drop_priv |
databases, tables, or views |
GRANT OPTION |
Grant_priv |
databases, tables, or stored routines |
LOCK TABLES |
Lock_tables_priv |
databases |
REFERENCES |
References_priv |
databases or tables |
EVENT |
Event_priv |
databases |
ALTER |
Alter_priv |
tables |
DELETE |
Delete_priv |
tables |
INDEX |
Index_priv |
tables |
INSERT |
Insert_priv |
tables or columns |
SELECT |
Select_priv |
tables or columns |
UPDATE |
Update_priv |
tables or columns |
CREATE TEMPORARY TABLES |
Create_tmp_table_priv |
tables |
TRIGGER |
Trigger_priv |
tables |
CREATE VIEW |
Create_view_priv |
views |
SHOW VIEW |
Show_view_priv |
views |
ALTER ROUTINE |
Alter_routine_priv |
stored routines |
CREATE ROUTINE |
Create_routine_priv |
stored routines |
EXECUTE |
Execute_priv |
stored routines |
FILE |
File_priv |
file access on server host |
CREATE TABLESPACE |
Create_tablespace_priv |
server administration |
CREATE USER |
Create_user_priv |
server administration |
| PROCESS | Process_priv |
server administration |
| PROXY | see proxies_priv table |
server administration |
| RELOAD | Reload_priv |
server administration |
| REPLICATION CLIENT | Repl_client_priv |
server administration |
| REPLICATION SLAVE | Repl_slave_priv |
server administration |
| SHOW DATABASES | Show_db_priv |
server administration |
| SHUTDOWN | Shutdown_priv |
server administration |
| SUPER | Super_priv |
server administration |
| [ALL PRIVILEGES] | server administration | |
| USAGE | server administration |
InnoDB和MySAM
- 现在都是默认使用InnoDB
- MySAM 比较老,以前用
区别:
| MySAM | INNODB | |
|---|---|---|
| 事务 | 不支持 | 支持 |
| 数据锁定方式 | 表锁定 | 行锁定 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间大小 | 小 | 大,约为MySAM的两倍 |
| 聚集索引 | 比普通索引多了个约束 | 叶子节点就是数据节点 |
在物理空间:
所有数据库都是以文件形式存储在data目录下,一组文件对应一个数据库,本质还是文件存储
Mysql引擎
- INNODB在数据库上只有一个*.frm, 以及上级目录的ibdata1文件
- MySAM
- *.frm 表结构
- *.myd 数据文件(data)
- *.MYI 索引文件(index)
索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
IO次数和数据结构的次数有关(树 – 就是高度) , 如果没有索引那就是一个数据一次IO
优缺点
https://zhuanlan.zhihu.com/p/29118331
分类
mysql的索引分为单列索引(主键索引(聚集索引),唯一索引(UNIQUE INDEX),普通索引(INDEX ))和组合索引.
单列索引:一个索引只包含一个列,一个表可以有多个单列索引.
组合索引:一个组合索引包含两个或两个以上的列,
聚集索引: 数据行的物理顺序与列值的顺序相同
非聚集索引: 该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。(普通索引,唯一索引,全文索引)
回表查询解决方式: 复合索引(覆盖索引)
sql
1 | -- 组合 |
覆盖索引: select 的 和查找的都是索引
索引的数据结构:
哈希:
B树
B+树
索引
LOG
TODO:
- P52 - p63 一些函数和语句: 我跳了
- P74 - P84 存储过程的其他东西 和 触发器 我跳了
- 还差索引
- 整理
参考资料
 wechat
wechat alipay
alipay



