
分布式
分布式
分布式理论
什么是分布式系统
建立在网络之上的软件系统
在《分布式系统原理与范型》一书中定义:分布式系统是若干独立计算机的集合, 这些计算机对于用户来说就像单个相关系统
分布式系统是由一组通过网络进行通信, 为了完成共同任务而协调工作的计算机节点组成的系统, 分布式系统的出现是为了用廉价的, 普通的机器完成单个计算机无法完成的计算, 存储任务. 其目的是==利用更多的机器, 处理更多的数据==
分布式的进化过程
- 刚开始是: 单一应用架构ORM
- 垂直应用架构MVC
- 分布式服务框架**(RPC, 并发)**
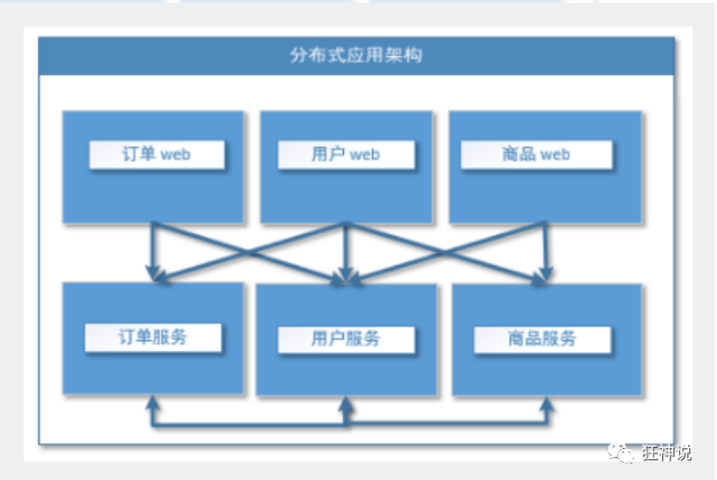
image.png
- 流动计算架构 提高机器利用率的资源调度和治理中心(SOA)
分布式的高性能体现
- 并行性(parallelism)
- 容错性 (fault - tolerance)
- 可用性: 因为系统是相对隔离的所以尽管出现了一些故障 还是可以运行的
- 可恢复性: 其中一个服务器坏了 修好了还能正常一样运行 减少一些不必要的重启
- 复制技术: 将数据做多个副本, 就算出现问题也能保证数据不出问题
- 在物理层面实现 ( 不同地方的计算机实现数据交互 )
- 实现了系统的隔离 会相对的安全 : (功能分开 利用网络通信来链接 其中一个服务崩溃 不会影响总体的服务)
- 可扩展性: 两倍的计算机 可以拥有两倍的处理性能(并行处理)或吞吐量 (理想条件)
分布式架构的问题
虽然分布式大大增加了系统的性能但是需要解决的问题也多了 数据一致性啊 传输速度和方案啊 因为服务器数量增加了 单一服务器出现的小概率问题 也会显现出来
一致性
强一致性 (每次修改数据同步所有服务器节点)(高消耗) : 因为数据同步时需要网络传输 如果每次操作都需要将所有服务器都同步 开销很大的
如果创建了副本 副本肯定不在同一个地方 这样的化通信时间也是问题
若一致性(修改数据不需要同步所有节点. 要有一些策略来保证获得数据时的正确性): 还是比较优秀的
还有一种处理方式 在获取数据时 : 多获取几个版本的 做到数据一致性
非易失性存储(Non-Volatile-Storage)
非易失性存储的数据更新时的代价很高
非易失性存储的管理技巧: LOG WAL Redo/Undo
MapReduce
2003年谷歌用来实现分布式计算海量数据的计算的一个技术 当然也是一种思想
Map和Reduce
看了知乎的一篇文章解释的很到位
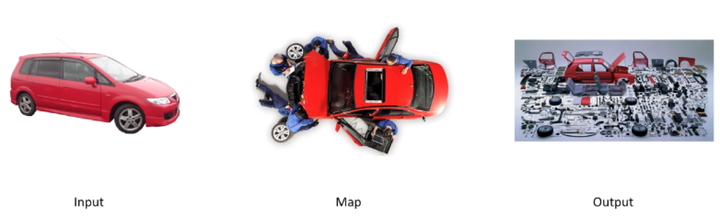
Map的本质实际上是拆解,比如说有辆红色的小汽车,有一群工人,把它拆成零件了,这就是Map。
img
那什么是Reduce呢?Reduce就是组合,我们有很多汽车零件,还有很多其他各种装置零件,把他们一阵拼装,变成变形金刚,这就是Reduce。

img
- MapReduce就是把文件输入拆解分类 然后按照你需要的方式传出结果(排序,筛选….)
工作流程
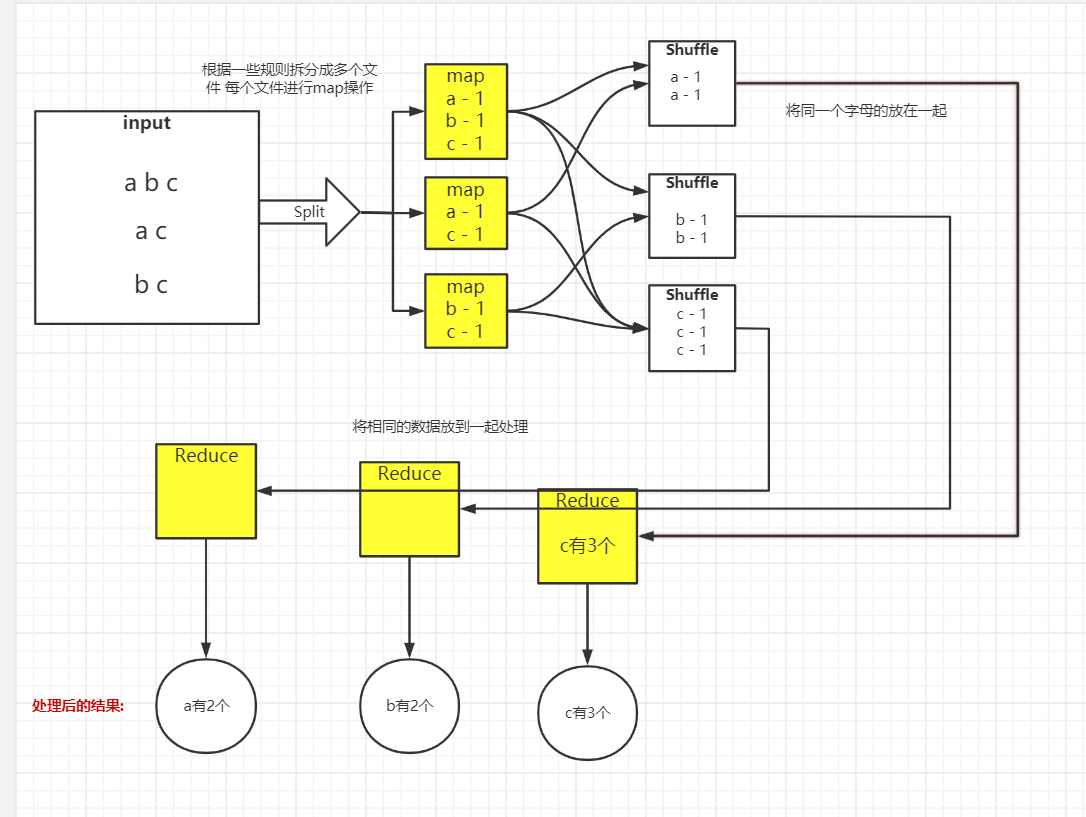
大致分为六部: Input, Split, Map, Shuffle, Reduce(归约函数), Finalize
举个例子 处理文件中相同数据的个数
MapReduce
当然 处理结果也可以作为下一步操作的输入文件
shuffle 传递时会产生流量 实际上这是大量的数据
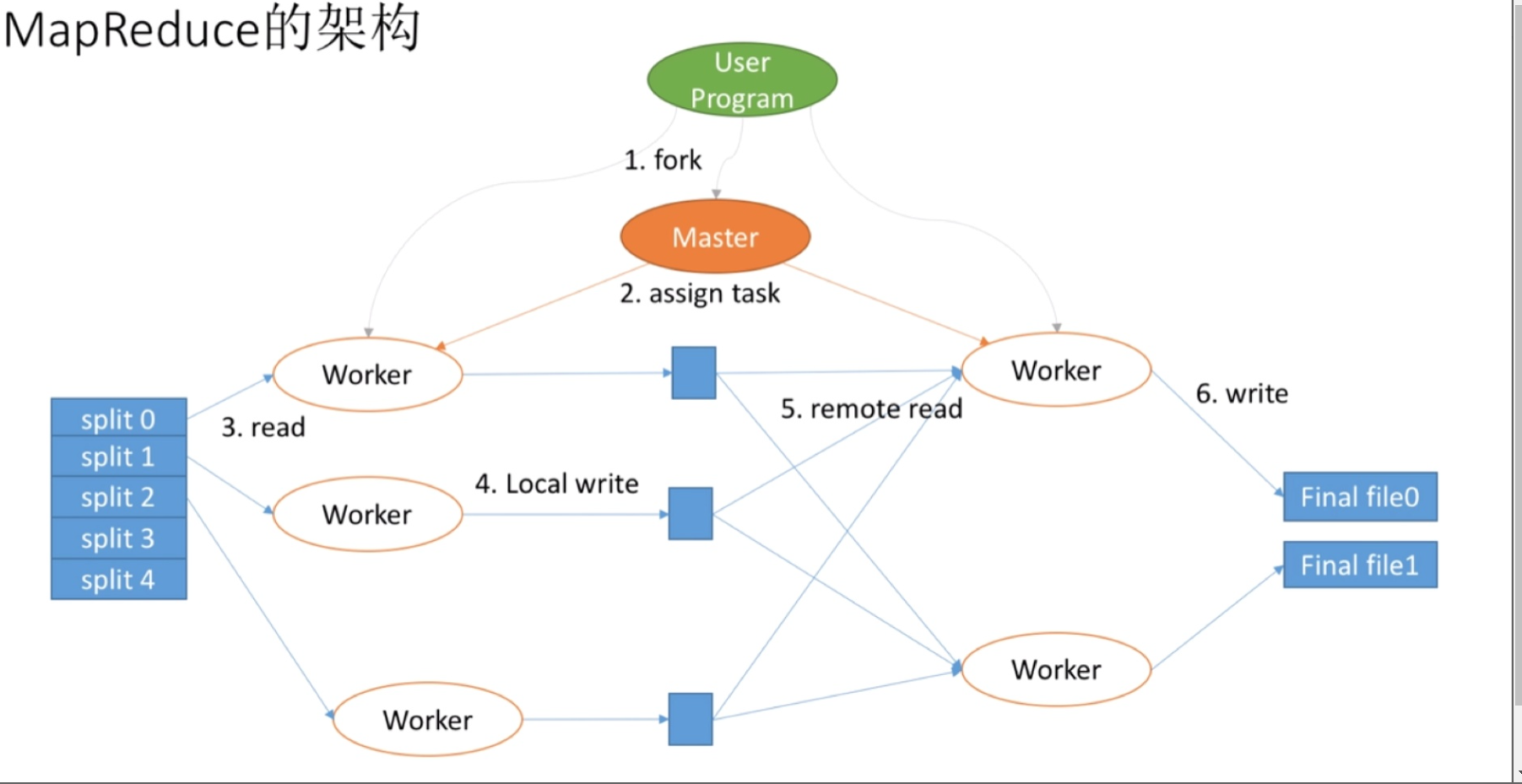
真实情况下MapReduce怎么用众多服务器实现呢
job: 处理业务逻辑的一个整体
task: 调用执行MapReduce叫一个Task
Worker: 程序申请时 由Master worker来负责调度 由不同的worker来进行map/Reduce 当然可以是不同的服务器
MapReduce架构
雪花算法 – 分布式中确保唯一id的算法
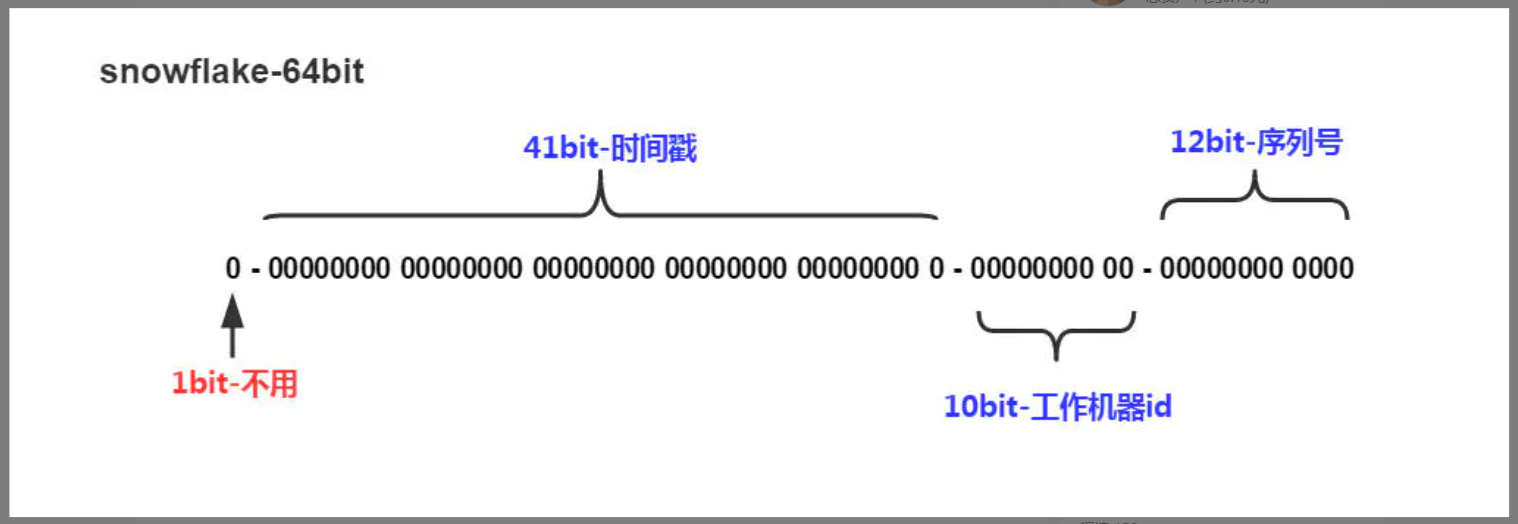
image-20200912161729887.png
- 加锁获取id 下面三组数据与运算
private long sequenceMask = -1L ^ (-1L << sequenceBits); 一个long类型的最大值(12位的1) 4096
-1L二进制全是一(反码的补码) 左移 sequenceBits(12) 位 得到 12位的1
- 时间戳 左移22位
如果序列号加一 与上 sequenceMask (12位的1)为0那么进入下一毫秒tilNextMillis
java
1 | private long tilNextMillis(long lastTimestamp) { |
- 机房号(左移17位) 和 机位id (左移12位) (一共1024个)
- 序列号 sequence
java
1 | if (lastTimestamp == timestamp) { |
参考资料
 wechat
wechat alipay
alipay



